SQL is the acronym for Structured Query Language.
SQL is the acronym that corresponds to the English expression Structured Query Language (understood in Spanish as Structured Query Language ), which identifies a type of language linked to the management of relational databases that allows the specification of different classes of operations between them. Thanks to the use of algebra and relational calculations, SQL offers the possibility of making queries with the aim of retrieving information from databases in a simple way.
The scientist Edgar Frank Codd ( 1923 – 2003 ) was the one who proposed a relational model for databases and created a sublanguage to access data from the calculation of predicates. Based on Codd 's work, IBM ( International Business Machines ) defined the language known as Structured English Query Language ( SEQUEL ).
SEQUEL is considered the predecessor of SQL, a fourth-generation language that was standardized in 1986 . The most primitive version of SQL, therefore, was the one called SQL-86 (also known as SQL1 ).
SQL Features
In essence, SQL is a high-level declarative language since, by handling sets of records and not individual records, it offers high productivity in coding and object orientation. An SQL statement can be equivalent to more than one program that uses a low-level language.
A database , experts say, involves the coexistence of multiple types of languages. The so-called Data Definition Language (also known as DDL ) is one that allows modifying the structure of the objects included in the database through four basic operations. SQL, for its part, is a language that allows data manipulation (Data Manipulation Language or DML ) that contributes to the management of databases through queries.
SQL makes it possible to manage relational databases.
How to build an efficient database
Every company that aims for a bright future, with possibilities for growth and expansion , must have a database, which will be different in each case, adjusting to the particular needs of each type of business, but which must be carefully prepared, with a solid and configurable structure, open to potential modifications without this threatening its integrity.
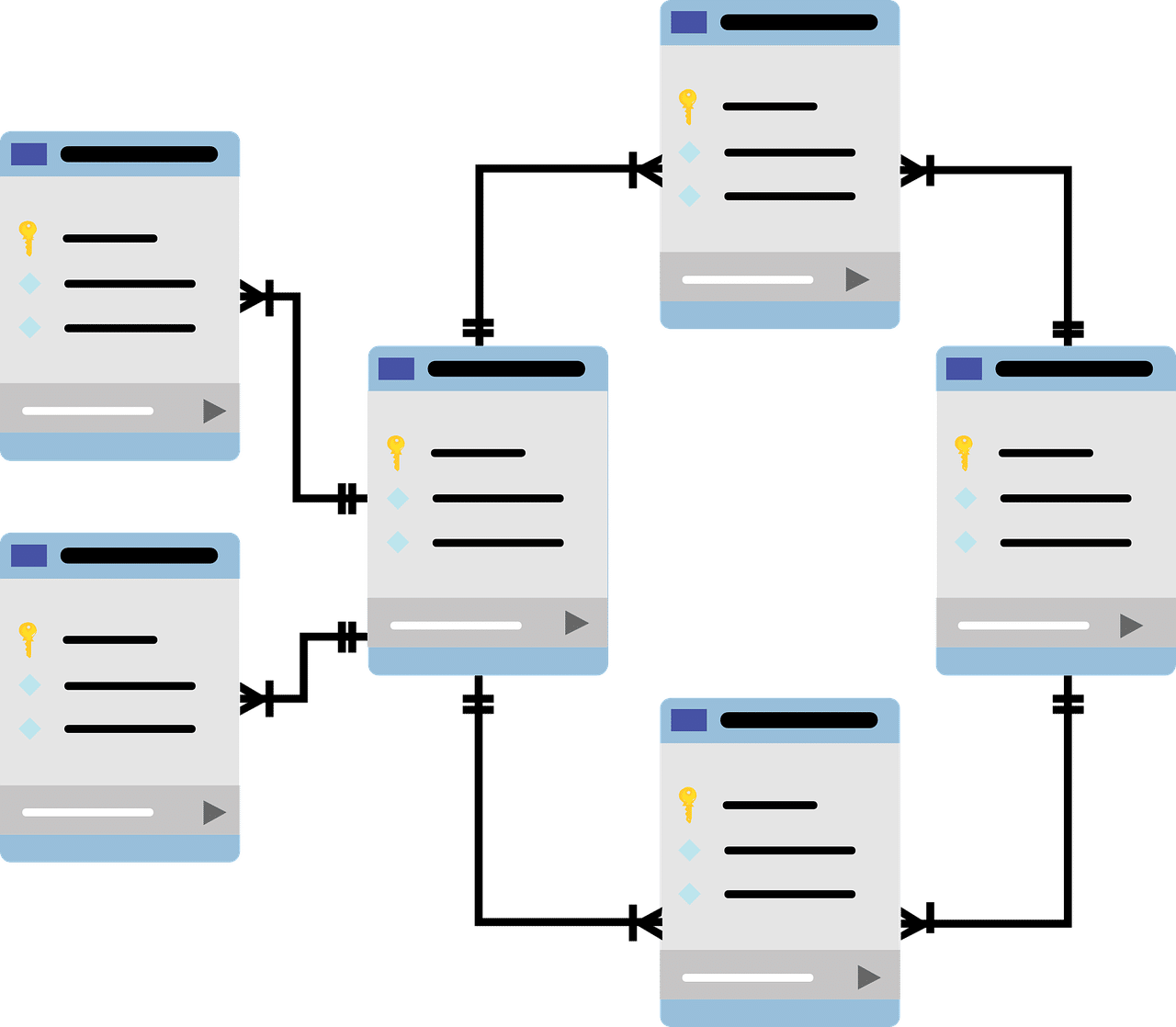
One of the basic points when building a database is indexing . To understand this concept, let's briefly look at a basic practical example: suppose a company wants to store its customers' personal information and track their transactions; To do this, one possibility would be to have a table for your data (name, surname, email address, etc.), another for the description of the products (item name, price, details) and one for sales. Before going on to detail which fields could be present in this last table, it is worth mentioning that the remaining ones are missing an essential element for good organization: a unique identification key .
Generally called ID , it is usually a positive integer (without decimals) that the database automatically assigns to each new record (in this case, each new customer or product) and that is never repeated, so that it identifies it from its birth (moment of creation) until death (when removed). In this way, if we take for example the record "103 Pablo Bernal [email protected] ", we notice that its ID is 103. What is its use? In short, searching for a customer whose first name is n , last name, a , and email, e , takes much more time than asking the database to return all the customer data with ID “103”. Although it is likely that in the first operation we will specify all your information , once the program finds it, we will be able to use this number for the rest of the queries.
Returning to the example, given that the customer and product tables would have their ID, relating them to the sales table is very simple; Its fields could be: transaction id, customer id, product id, date, observations. Without getting into technicalities, it is clear that each sale contains much more information than what can be seen at first glance , since, for example, a customer's ID helps us access all of their data in the corresponding table. In practice, it goes without saying that the complexity can be much greater, but it is important to start with the basics to understand the importance of solid and efficient relationships .