 The term covariance is not part of the dictionary prepared by the Royal Spanish Academy ( RAE ). The concept, in any case, is used in the field of statistics and probability to name the value that reflects the degree of joint variation that is registered in two random variables taking their means as a measure.
The term covariance is not part of the dictionary prepared by the Royal Spanish Academy ( RAE ). The concept, in any case, is used in the field of statistics and probability to name the value that reflects the degree of joint variation that is registered in two random variables taking their means as a measure.
Covariance, therefore, allows us to discover if the variables maintain a dependency link . The data also contributes to knowing other parameters.
A function that assigns a value to the result of a random experiment , usually of a numerical type, is known as a random variable . A random experiment , on the other hand, is one that can yield different results even if it is performed more than once under the same conditions, so that each experience becomes impossible to predict and, therefore, to reproduce.
A very common example of a random experiment , which we can try in our daily lives, is the throwing of a dice: even if it is thrown on the same surface, with the same hand or cup, and applying more or less the same force and direction, it does not It is possible to predict which of its faces will be pointing up.
If low values of one variable correspond to low values of another variable, or if the same occurs with high values of both, the covariance has a positive value and is classified as direct . On the other hand, if the low values of one variable correspond to the highest values of another variable and vice versa, the covariance is negative and is defined as inverse . The existing trend in the linear relationship established between the variables, in this way, is expressed by the covariance sign .
There are different formulas to calculate the covariance. It can be said that covariance is the arithmetic mean that arises from the product of the deviations of the variables with respect to their own means.
Suppose the variables are the results of the History and Geography evaluations of five students:
History Grades (P) of the five students: 6, 5, 7, 7, 4 (total = 29)
Geography Grades (S) of the five students: 7, 3, 4, 3, 5 (total = 22)
Then you have to tabulate, multiplying the results of each student's evaluations:
P x S: 42 (since 6 x 7 = 42), 15 (5 x 3), 28 (7 x 4), 21 (7 x 3), 20 (4 x 5). Total sum of results = 126)
Mean P: 29 / 5 = 5.8
S average: 22 / 5 = 4.4
Finally:
PS Covariance: (126 / 5) – 5.8 x 4.4
PS covariance: 25.2 – 5.8 x 4.4
PS Covariance: 25.2 – 25.52
PS Covariance: -0.32
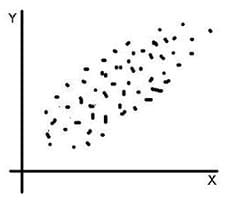 In addition to knowing whether two given random variables have a mutual dependence link, covariance is used to estimate parameters such as the regression line and the linear correlation coefficient .
In addition to knowing whether two given random variables have a mutual dependence link, covariance is used to estimate parameters such as the regression line and the linear correlation coefficient .
The regression line is also known as linear fit or linear regression , and is a concept belonging to the field of statistics that includes a mathematical model used to approximate the dependence that exists between a group of variables and a random term.
The linear correlation coefficient , on the other hand, is an indicator of the direction and strength of a linear relationship (in mathematics, what occurs if the value of one magnitude depends on that of another) and a proportionality (a ratio or constant relationship that occurs between magnitudes that can be measured) between two statistical variables (they are characteristics that can fluctuate, with values that can be observed and measured).
It is important to differentiate the following two types of covariance: that which occurs between two random variables, which is considered a property of the joint distribution, that is, of the events of both that occur simultaneously; the sample, which is used as a statistical estimation of the parameter .